




Dark Data: Unlocking the ~90% You Don’t Use
.jpg)


In an era where every organization is racing to become “data-driven,” it’s startling to realize that most are using only a fraction of the information they collect. Beneath the dashboards, analytics, and AI models lies a vast and largely unseen universe of information, unstructured, unclassified, and underutilized. This is what experts call dark data.
According to Gartner, dark data refers to the information assets organizations collect, process, and store during routine business activities but fail to use for analytics, business relationships, or monetization. In simple terms, it’s everything your organization captures but never looks at again, from old emails and forgotten logs to call transcripts and IoT sensor readings.
The scale of this hidden asset is staggering. IBM estimates that as much as 90% of sensor-generated data, one of the largest sources of information today is never analyzed. Companies spend millions storing and securing this data, but few extract value from it. It’s like owning an oil field and never drilling a well.

This isn’t just a missed opportunity; it’s an operational paradox. Dark data costs money to store, maintain, and protect, yet it simultaneously represents one of the richest untapped reservoirs of organizational intelligence. From emails containing unrecorded customer insights to system logs that hint at performance issues, dark data is both a burden and a potential goldmine.
The Anatomy of Dark Data
Dark data can take many forms and most of it doesn’t fit neatly into rows and columns. Think of logs and telemetry generated by servers, transcripts from customer calls, recordings from meetings, IoT sensor readings, employee chat histories, drafts of reports, or even scanned documents sitting in forgotten folders. According to Komprise, most dark data is unstructured or semi-structured, which means it cannot be easily searched or analyzed using traditional tools.
Why does so much data go dark? Part of the problem lies in metadata poverty when files and records aren’t tagged or indexed properly, they become effectively invisible. Legacy formats and siloed systems make the problem worse, creating islands of information that no one can access. Many organizations also fall prey to what might be called data hoarding: the instinct to store everything “just in case,” assuming storage is cheap and analysis can come later. But later rarely comes.
A Splunk survey revealed that over 60% of organizations believe at least half of their data is dark, and one-third said 75% or more of it is never used. In industrial contexts, where IoT sensors and telemetry systems generate continuous streams, IBM and others estimate that up to 90% of the data produced is simply never analyzed. (SiliconANGLE)
The reasons are rarely technological alone. Dark data reflects human and organizational realities: limited time, competing priorities, lack of incentives, or the absence of a clear business case for analysis. In effect, the more data we create, the more we ignore.
Key Takeaways
- Dark data includes the forgotten emails, logs, sensor data, and transcripts that organizations collect but never use.
- Poor metadata, siloed systems, and “store-everything” mindsets make it hard to utilize.
- Studies suggest that between 80% and 90% of corporate data is dark highlighting a vast pool of untapped value.
From Capture to Activation: How to Build a “Light Pipeline”
To harness dark data, companies need a deliberate framework, a process that takes raw, unstructured information and gradually converts it into something searchable, governed, and valuable. A practical way to visualize this is through a reference architecture that moves through six stages: capture, classify, vectorize, govern, activate, and feedback.
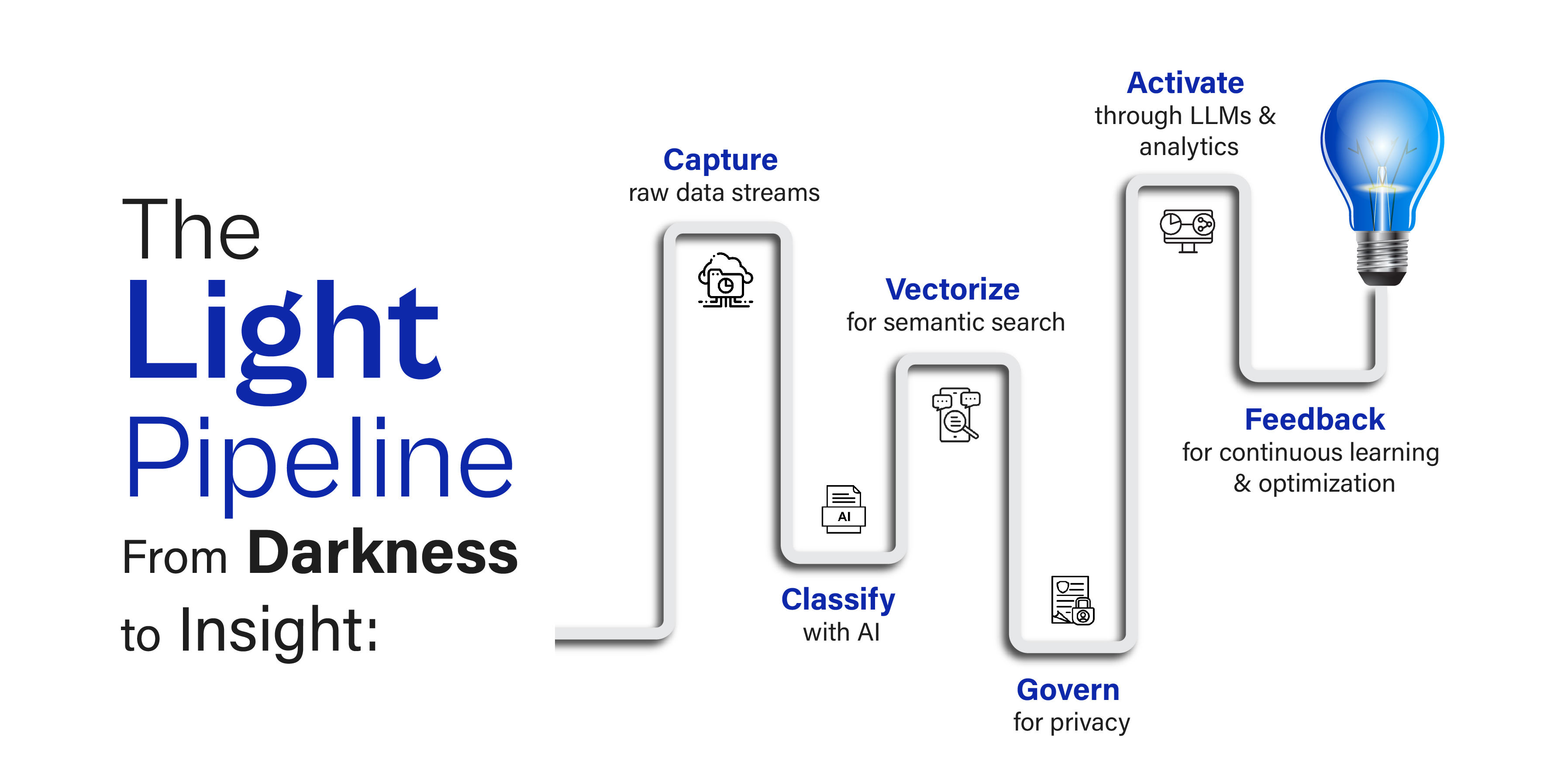
The process begins with capture, which involves systematically ingesting all forms of data into a unified environment. This can mean streaming real-time logs, pulling emails, syncing from cloud drives, or collecting IoT telemetry. Modern data lake architectures allow organizations to ingest data in its raw form using a “schema-on-read” approach, meaning the data doesn’t have to be perfectly structured before being stored. At this stage, even simple metadata, timestamps, file origin, or context tags can later prove invaluable.
Next comes classification, where the goal is to make dark data discoverable. Using natural language processing (NLP), entity recognition, and pattern detection, classification tools can assign topics, categories, and sensitivity levels automatically. Without this step, dark data remains a haystack without a needle, impossible to search or link to business needs.
Once data is categorized, the next step is vectorization, converting unstructured information into numerical embeddings. By transforming text, images, or audio into vectors, organizations make their data machine-readable in a semantic sense. This is the same technology that powers large language models (LLMs) and enables what’s known as retrieval-augmented generation (RAG), where AI systems can retrieve relevant context from large datasets before generating answers. In practice, this means an employee could query all past call transcripts or maintenance logs using natural language and get precise, context-aware answers.
But no activation is sustainable without governance. As soon as previously dormant data becomes visible, issues of access, privacy, and compliance emerge. A governance layer ensures that only authorized users can access sensitive content, while anonymization and retention policies protect both privacy and regulatory compliance. This layer also tracks lineage, recording how and when data changes hands or gets transformed.
Finally comes activation, where the value of the entire pipeline becomes evident. Organizations can integrate dark data into dashboards, feed it into LLM-based assistants, or use it for anomaly detection and predictive maintenance. For instance, a customer service team could query years of chat logs to identify recurring issues, or a manufacturing unit could use previously ignored sensor logs to predict failures before they happen.
The process is cyclical, not linear. Once some data is activated and used, the system learns from usage patterns, improves classification accuracy, and helps decide what can be archived or deleted, forming a sustainable feedback loop.
Key Takeaways
- Turning dark data into value requires a structured process: capture → classify → vectorize → govern → activate → feedback.
- Vectorization and semantic search (via LLMs and RAG) are transforming how unstructured data is used.
- Governance and privacy controls are essential to avoid new risks as old data becomes visible.
Early Wins and Real-World Impact
Every digital transformation leader wants quick wins, and dark data offers plenty. The most immediate opportunities often emerge in industries with large volumes of unstructured text and logs.
In insurance and warranty management, for instance, claims quality assurance can be revolutionized by mining adjuster notes, emails, and attachments. Similar patterns across past claims can be detected automatically, enabling fraud reduction and more consistent decision-making. In call centers, where thousands of hours of conversation sit unused, semantic search across transcripts can uncover systemic customer issues, track sentiment, and even flag compliance risks in real time.
In heavily regulated industries like healthcare, energy, or manufacturing, operational logs and safety reports contain hidden indicators of compliance violations or potential hazards. Surface those patterns early, and organizations can prevent costly incidents while satisfying audit requirements faster. The same principle applies in retail and telecom: analyzing customer feedback logs or field engineer notes can uncover trends before they escalate into major service issues.
The business impact is measurable. Companies that successfully operationalize even a fraction of their dark data report tangible benefits: faster response times, better risk detection, lower costs, and improved decision accuracy. The transformation starts small, often with one department or data source — but scales as the organization realizes that insight was never missing; it was merely buried.
Key Takeaways
- High-value starting points include insurance claims QA, call-note mining, and compliance monitoring.
- Early projects can demonstrate measurable KPI uplifts, in accuracy, speed, and cost.
- Once dark data is illuminated, it naturally feeds new applications and analytics streams, multiplying impact over time.
Cost Models & Trade-offs: Storage, Retrieval, Transformation
When deciding whether to bring dark data into the light, organizations must wrestle with a three-way cost trade-off: storage, transformation (compute/processing), and retrieval/access. What seems “cheap” in one dimension may be expensive in another.
The Storage / Access Continuum
In cloud or hybrid infrastructures, data is usually tiered across hot, warm, cold, and archival storage, with progressively lower costs but higher access latency. For example, Amazon’s S3 Glacier offers archival storage at ~$0.004/GB per month for seldom-accessed data, but introduces costly and slow retrievals (3–5 hours or more) when you need to revive it. (Wikipedia) Azure’s Blob Archive tier similarly charges low monthly storage rates while imposing extra costs when “rehydrating” data back to online tiers. (Microsoft Learn)
Retrieval expenses vary significantly: some cloud providers charge per gigabyte retrieved or per request, especially for infrequent or archival classes. (Cyfuture Cloud) If your dark data activation involves frequent re-access, the retrieval cost may dwarf the storage savings.
Meanwhile, internal or on-prem infrastructure has its own cost profile. Back in 2019, Gartner estimated that the average annual cost per raw terabyte (in raw capacity) was around USD 738 (covering power, cooling, hardware amortization, support, etc.). (Reddit) That baseline doesn’t include compute or transformation costs.
Transformation & Compute Costs
Dark data in raw form is rarely useful. The task of classification, embedding (vectorization), indexing, and linking to business metadata consumes compute, memory, and sometimes costly GPU or cluster time. Especially for large volumes of text, media, or time series, embedding models or feature extraction pipelines can become substantial line items.
If you try to transform everything preemptively, you risk over-provisioning. A better strategy is often just-in-time transformation or lazy embedding, where you only process data that’s actually being queried or activated frequently.
Advanced strategies include cold-to-hot promotion: data that is accessed increases in “hotness” and gets reprocessed more fully over time, while untouched data remains minimally processed.
Hybrid Strategies & Multi-cloud / Multi-tier Optimization
In research and scientific computing, one approach to reducing cloud costs is to distribute data across multiple providers (or internal vs external) and dynamically shift data depending on use patterns. For example, an algorithm might choose to delete and regenerate seldom-used data rather than store it permanently. (arXiv)
Hierarchical Storage Management (HSM), a well-established concept, automates the movement of data between media types (SSD, HDD, tape/optical) based on access patterns. (Wikipedia) A dark data pipeline can incorporate HSM principles: keep only high-value embeddings and metadata in fast storage, demote older or less used content deeper into archival tiers.
A Simple Cost Comparison Sketch
Consider a dataset of 100 TB of dark logs:
- Hot (standard) storage: USD 0.023/GB/month → ~$2,300/month
- Archive tier: USD 0.004/GB/month → ~$400/month
If retrieval costs for archive usage are $0.01/GB, retrieving even just 10 TB in a month adds $100 in retrieval cost, eating into your savings. Meanwhile, embeddings and classification compute might cost thousands of dollars depending on scale and complexity.
Hence, the decision framework looks like:
- How often will this data be accessed or activated?
- How costly is transforming it?
- What latency can your application tolerate?
- When is archival deletion acceptable?
By modeling each dimension, the “value breakpoint” becomes clearer.
Data Risk, Privacy & Retention in Unstructured Stores
Unlocking dark data isn’t just a technical exercise; it’s also exposing new risk surfaces. Previously hidden emails, logs, transcripts, or multimedia may contain sensitive personal data (PII), trade secrets, compliance triggers, or litigation liabilities. Approaching risk with intention is essential.
Exposure Risks & Re-identification
Even if data is “anonymized” or “de-identified,” re-identification is always a threat, especially when adversaries can combine multiple datasets. The process of data re-identification involves matching anonymized records with external information (e.g., public registries) to reconstruct identities. (Wikipedia) Regulators and privacy experts caution that naive anonymization is often insufficient protection.
Anonymization, Pseudonymization & Techniques
Anonymization seeks to irreversibly remove identifiers so that subjects can no longer be recognized. Truly anonymized data falls outside many privacy regulation scopes (e.g. GDPR), because it no longer qualifies as “personal data.” (GDPR Summary)
Pseudonymization (replacing identifiers with surrogate keys) is less stringent: it retains structural integrity while masking identity. Under GDPR, pseudonymization is classified as a safeguard (rather than outright anonymization) since re-identification is possible with additional information. (Wikipedia)
Common techniques include:
- Masking or tokenizing names, emails, and geolocations
- Shuffling or generalizing date or numeric fields
- K-anonymity, differential privacy methods
It’s often best to adopt a risk-based approach, where each attribute is assessed for re-identification probability relative to context (e.g., combining attendance logs, timestamps, and location). (Real Life Sciences)
Retention & Deletion Policies
One of the hardest challenges with dark data is justifying how long to hold it. Regulatory regimes like GDPR emphasize purpose limitation and that retention must be bound to a legitimate cause “we might need it later” is insufficient justification. (gallio.pro)
Best practices include:
- Define explicit retention periods for categories of data (e.g. transcripts, logs, emails)
- Automate lifecycle management so that expired data is flagged, archived, or securely deleted
- Document retention rationales and decisions for auditability
- Use secure deletion methods (zeroing, overwriting) instead of “soft delete.” (gallio.pro)
Governance, Access & Auditing
As dark data becomes surfaced, governance is non-negotiable. Role-based or attribute-based access control must accompany data activation. Each query or transformation should be logged. Audit trails must show who accessed what, when, and why.
Lineage metadata — showing how data moved from raw to transformed to queryable, is critical for traceability, compliance, and debugging.
In regulated industries, data that passes through multiple systems (e.g. transcripts fed into LLMs) might carry downstream risk: ensuring that embeddings don’t inadvertently carry sensitive fragments is necessary.
Key Takeaways
- Revealing dark data opens up privacy and compliance risks if not managed carefully.
- True anonymization is rare; pseudonymization helps but must be contextually safe.
- Retention policies must be explicit, automated, and defensible.
- Governance (RBAC, audit trails, lineage) is essential to responsibly unlock dark data.
Implementation Challenges & Best Practices
While the vision is compelling, many organizations stumble in execution. Turning the theory into working systems requires more than just good architecture.
Skills & Tooling Gaps
Many data teams lack expertise in embedding models, vector search systems, or metadata classification. Off-the-shelf tools are emerging, but maturity varies, especially for nontextual data (audio, video, sensor). Hiring or partnering with AI/ML specialists is often necessary.
Organizational Silos & Change Resistance
Dark data lives in functional silos: operations, IT, maintenance, support. Centralizing it requires breaking down barriers, aligning incentives, and driving adoption. Business units may resist exposing internal notes or logs. Leadership must support cross-functional integration.
Project Prioritization & Scope Control
Trying to ingest and activate all dark data at once is unrealistic. Instead, pick a pilot domain (e.g. call transcripts, safety logs) with clear metrics and ROI potential. Show success, then scale outward.
Use an MVP-first approach: minimal ingestion + classification for a subset of data, then activate, measure, and iterate.
Monitoring & Sustainability
Once data is “lit,” usage may evolve. Monitor access patterns, classification accuracy drift, and embedding quality, and adjust the pipeline accordingly. Feedback loops are essential: stale or unused data should be deprioritized or relocated.
Don’t forget maintenance burdens — model retraining, re-indexing, schema drift, and vector store upgrades all require ongoing investment.
Future Trends & Outlook
Looking ahead, the frontier of dark data activation is bright. A few themes are emerging:
- Model-driven indexing & embedding: Embeddings become first-class metadata, supplanting rigid schemas.
- Self-serve dark data platforms: Data consumers may explore their own dark datasets through intuitive interfaces, reducing reliance on central teams.
- Edge pre-processing: Internet-of-things devices may pre-classify or embed data locally, reducing ingestion bulk.
- Zero-dark ambition: Some organizations may target eliminating dark data over time, though more realistically, they aim for manageable dormancy thresholds.
- Privacy-aware embeddings & encryption: Research is emerging into storing encrypted embeddings or privacy-preserving models to reduce risk exposure.
In short, the technical, organizational, and regulatory challenges are surmountable and the potential is compelling. As systems mature, dark data could shift from being a scary burden to a core competitive advantage.
Conclusion
For years, organizations have been obsessed with collecting data, sensors, devices, logs, conversations, transactions, yet most of it remains unseen and unutilized. This silent accumulation has created a paradox: we are drowning in information but starving for insight. Dark data represents this paradox in its purest form, the invisible 90 percent of organizational knowledge lying dormant in servers and clouds across the world.
But today, a confluence of technologies, from semantic search to large language models and vector databases has made it possible to turn what was once noise into knowledge. With thoughtful architecture, ethical governance, and a clear sense of purpose, dark data can evolve from being a liability into a living source of intelligence. The shift requires reimagining data not as static archives but as dynamic assets that can continuously generate value when paired with AI-driven activation.
Yet illumination comes with responsibility. As organizations bring forgotten data to light, they must guard against privacy breaches, bias, and misuse. Governance frameworks, retention discipline, and responsible AI practices are as important as the pipelines themselves. The goal is not to expose everything but to surface what matters, safely, contextually, and purposefully.
The promise of dark data lies not in quantity but in connection. When systems can link a customer email to a support log, a sensor reading to a maintenance record, or a transcript to a compliance insight, the true intelligence of an enterprise begins to emerge. The companies that master this art will not just analyze data, they will understand themselves more deeply.
In the end, the journey from darkness to insight is not about data management. It’s about vision, the willingness to look beneath what’s visible and transform hidden fragments into decisions that define the future.
Biological data is permanent. A breach isn’t just technical, it’s personal, clinical, and national. As genomics, AI, and connected devices redefine healthcare, cyberbiosecurity must evolve from an afterthought to a core defense strategy.
Let’s secure the future of bio-digital innovation, responsibly and strategically.
At Cogent Infotech, we help organizations implement:
- FDA-aligned cyberbiosecurity governance
- Secure AI & bioinformatics frameworks
- Supply chain and SBOM resilience
Book a consultation to build your cyberbiosecurity roadmap.
.jpg)

